

Questions 5 to 8 are in this post. For 1 to 4 questions click here.
5) Distinct SubString
Problem Description
Given a string and a set of rules, process the string in such a way, that it produces some unique substrings. Print all the longest possible substrings with distinct characters, following the below mentioned rules:
- String should be processed from left to right
- Substring should be longest possible consecutive stream of different characters (longest substring). As soon as a repeating character is encountered, consider the already processed characters as the longest substring achieved in that pass
- Once a pass is over, the next pass begins from the next index that was used in the previous pass. Simply put, first pass will always begin from first character, second pass will begin from second character, so on and so forth
- Just to make it explicit – a subsequent pass cannot process characters whose index is smaller than the beginning index of the current pass. For example, second pass cannot process first character, third pass cannot process first and second characters, so on and so forth
- A longest substring can be of two types – a Proper substring and an Improper substring
- A proper substring is one which satisfies two criteria
- All characters in a proper substring are fully contained in a previously identified longest substring and in same order
- Also, indices of proper substring are those that are completely overlapped by previously identified longest substring and in same order
- E.g. if string is “abcdc”, the first longest substring is “abcd” and its indices are from 1 to 4 (assume 1-based index)
- Now, “bcd” is a proper substring of “abcd” because not only “bcd” is completely contained in “abcd“, but also indices of “bcd” are 2 to 4, which completely lie in the range 1 – 4
- An Improper substring is one which satisfies only first criteria above.
- E.g. Consider string “abcdcbcd“, the first longest substring is “abcd” and its indices are from 1 to 4 (assume 1-based index)
- Now, “bcd” at index 6 to 8 is an improper substring of “abcd” because even though it satisfies the first criteria of proper substring, it does not satisfy the second criteria
- In order to capture all possible longest substrings, ignore Proper substrings and retain Improper substrings
- Additional restrictions that exist on which longest substrings can be retained are as follows
o When a longest substring is broken by a repeating character which is same as the first character of the substring, then two rules apply
- If that substring is the first longest substring then retain that substring
- Else, ignore that substring
- Example – Consider string “abcdabca” – first longest substring “abcd” which is broken by ‘a’, is retained. However, second pass which generates second longest substring “bcda” is to be ignored because the substring starts and is also broken by the same character ‘b’. Same logic applies for third longest substring “cdab”, which is to be ignored
- When processing is complete, arrange all longest possible substring(s) in lexicographical order and print it as output
Constraints
0 < N <= 10000
String consist of all lowercase characters {a - z}Input
First line contains an integer N which denotes the length of string
Second line contains the actual string
Output
Print all the longest possible substring(s) with distinct characters, delimited by space character, while maintaining the rules mentioned above
Time Limit
1Examples
Example 1
Input
8
abcdcbacOutput
abcd bac dcbaExplanation:
String: abcdcbcd
For illustration purpose and better understanding, substrings of interest are marked in bold and are underlined
- In the first pass, longest substring is “abcd” (abcdcbac). Since there is ‘c’ which is already in the substring, we retain only “abcd” and move forward.
- In the second pass, longest substring is “bcd” (abcdcbac). Since the next character is ‘c’ and “bcd” is a proper substring of previously captured longest substring “abcd”, we discard this substring.
- In the third pass, longest substring is “cd” (abcdcbac). Since the next character is ‘c’ and “cd” is already a proper substring of “abcd”, we discard this substring also. Also, substring “cd” is discarded because, the starting character of this substring and the first repetitive character is same. Hence “cd” is discarded because of two rules.
- In the fourth pass, longest substring is “dcba” (abcdcbac). Since the next character is ‘c’ and this substring is not contained in any previously retained longest substring, we retain “dcba” and move forward.
- In the fifth pass, longest substring is “cba” (abcdcbac), Since the next character is ‘c’ and “cba” is a proper substring of “dcba”, we discard this substring.
- In the sixth pass, longest substring is “bac” (abcdcbac). We consider this substring because it is not a part of any previously retained longest substrings.
- In the seventh pass, longest substring is “ac” (abcdcbac). Since “ac” is a proper substring of “bac”, we discard this substring.
- In the eighth pass, longest substring is “c” (abcdcbac). Since “c” is a proper substring of “bac”, we discard this substring too.
Since the length of the string is 8, we made eight passes over the string to compute longest substrings. Notice that in the current pass, all the characters whose index is lower than the index of the beginning character from where the current pass begins, are not considered.
Hence, final output with retained longest substrings sorted in lexicographical order is – “abcd bac dcba”.
Example 2
Input
8
abcdcbcdOutput
abcd bcd dcbExplanation:
String: abcdcbcd
For illustration purpose and better understanding, substrings of interest are marked bold and underlined
- In the first pass, longest substring is “abcd” (abcdcbcd). Since there is ‘c’ which is already in the substring, we retain only “abcd” and move forward.
- In the second pass, longest substring is “bcd” (abcdcbcd). Since the next character is ‘c’ and “bcd” is a proper substring of previously captured longest substring “abcd”, we discard this substring.
- In the third pass, longest substring is “cd” (abcdcbcd). Since the next character is ‘c’ and “cd” is already a proper substring of “abcd”, we discard this substring also.
- In the fourth pass, longest substring is “dcb” (abcdcbcd). Since the next character is ‘c’ and this substring is not contained in any previously retained longest substring, we retain “dcb” and move forward.
- In the fifth pass, longest substring is “cb” (abcdcbcd), Since the next character is ‘c’ and also “cb” is a proper substring of “dcb”, we discard this substring.
- In the sixth pass, longest substring is “bcd” (abcdcbcd). We consider this substring because although it is a part of previously retained longest substring “abcd”, it is an Improper substring. Hence, we retain this substring.
- In the seventh pass, longest substring is “cd” (abcdcbcd). Since “cd” is a proper substring of “bcd”, we discard this substring.
- In the eighth pass, longest substring is “d” (abcdcbcd). Since “d” is a proper substring of “bcd”, we discard this substring too.
Since the length of the string is 8, we made eight passes over the string to compute longest substrings. Notice that in the current pass, all the characters whose index is lower than the index of the beginning character from where the current pass begins, are not considered.
Hence, final output with retained longest substrings sorted in lexicographical order is – “abcd bcd dcb”.
6) Best Sequence
Problem Description
Some of the keys of Ajith’s Laptop’s keyboard are damaged and he is not able to type those keys. He has to complete his assignment and submit it the next day and since it is midnight he will not be able to give his laptop for repair. So he decides to make a character sequence of all the damaged keys in a sequence that he can copy and paste and make a word out of them.
Ajith needs to type a paragraph with all the characters in lower case. Help Ajith to find out the best permutation of the sequence of the characters (corresponding to the damaged keys) per word, that can be used while typing the paragraph, i.e. the sequence that will require least insertion and deletion while typing a word. Consider paste operation to be of one keystroke. Ignore the copy operation.
Recursively apply the same procedure for all the words in the paragraph. This way you will get the best combination that should be selected for that word. Finally, find out how many different words exist per character sequence combination. The combination that is the best for maximum words should be printed as output. If there are more than one candidates for best character sequence print the lexicographically smallest character sequence as output.
Refer the examples section for better understanding.
Constraints
0 < Number of words in paragraph < 50
0 < Number of damaged keys <= 6Input
First line contains the paragraph P that is to be written.
Second line contains the characters that represent the damaged keys delimited by white space.
Output
One line containing the best character sequence which can be used to copy paste and construct the words.
Time Limit
1Examples
Example 1
Input
supreme court is the highest judicial court
s uOutput
suExplanation
There are two possible combinations of the damaged keys i.e. either su or us.
For word supreme, su is suitable as it requires only paste operation
For court, us is suitable as it requires one keystroke for deletion
Similarly, for is, su is suitable because it requires one keystroke for deletion
Finally, we get su suitable for words {supreme, is, highest} and us suitable for words {court, judicial, court}. We get su and us suitable for 3 words each.
Since su is lexicographically smaller than us, the output will be su.
Example 2
Input
ginnestinggin gniinginging
n i gOutput
ginExplanation
There are six possible combinations of the damaged keys viz. {nig, ngi, ing, ign, gni, gin}.
For the first word, nig requires 36 keystrokes, ngi requires 26 keystrokes, ing requires 21 keystrokes, ign requires 26 keystrokes, gni requires 32 keystrokes and gin requires 15 keystrokes to type the word. Hence, gin sequence is suitable for the first word.
Similarly, for the second word, nig requires 28 keystrokes, ngi requires 17 keystrokes, ing requires 16 keystrokes, ign requires 29 keystrokes, gni requires 28 keystrokes and gin requires 17 keystrokes to type the word. Hence, ing sequence is suitable for second word.
Since, both ing and gin sequence are suitable for 1 word each and gin is lexicographically smaller than ing. Hence the output is gin.
7) Clever Traveler
Problem Description
You are given the data of travel schedule of a traveler and prices of travel passes provided by N different companies. There is no restriction on the number of times one can buy the passes. However the objective is to buy optimal number such that the traveling cost is minimized. You can buy passes from different companies for different days.
The passes can be single day or multi-day pass. In case of multi-day pass the pass is valid for those many travels on consecutive days only. For e.g. a 10-day pass can be used to travel 10 times from Day 1 to Day 10. The pass expires at the end of 10th day. Hence it can not be used for any further travel. Similarly a N day pass expires at the end of Nth day from the day of issue.
For better understanding refer to Examples section.
Constraints
0 < N <= 5
0 < M < 10 ^ 5Input
First line contains five space separated integers in ascending order denoting the number of days of validity for that pass.
Second line contains an integer N which denotes number of travel companies that provide passes.
Next N lines contain five space separated integers which denotes the price of the ith pass offered by nth travel company where 1 <= n <= N.
Next line contains an integer M which denotes the number of days the traveler has to travel.
Next line contains M space separated integers. Each number denotes the day number that the traveler has to travel on
Output
Minimum cost of travel for given travel schedule factoring in pass cost offered by different companies.
Time Limit
1Examples
Example 1
Input
1 3 5 7 9
2
1 3 5 5 7
1 3 4 6 8
12
1 2 3 4 5 6 7 8 9 10 11 15Output
10Explanation
The input format conveys the following information
First three lines convey the following.
| Pass Cost | 1-day | 3-day | 5-day | 7-day | 9-day |
|---|---|---|---|---|---|
| Company 1 | 1 | 3 | 5 | 5 | 7 |
| Company 2 | 1 | 3 | 4 | 6 | 8 |
Fourth line conveys that the traveler has to travel for 12 days.
Fifth line conveys on what days does he need to travel.
Note that the traveler needs to travel on 11 consecutive days, while the 12th travel is a few days apart.
So if the traveler purchases a 7-day pass from company 1 and and a 5-day pass from company 2, then at the end of twelve days he will have traveled 11 times at a cost of 9 (5 + 4).
Further the traveler can purchase a 1-day pass from either company since cost is the same. Thus the overall minimum travel cost is 10 (9 + 1). Hence output is 10.
Example 2
Input
1 5 10 15 30
3
1 4 9 11 22
1 4 8 12 26
2 8 13 17 37
30
1 2 3 4 5 6 7 8 9 10 22 23 24 25 26 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47Output
23Explanation
The input format conveys the following information.
First three lines convey the following.
| Pass cost | 1-day | 5-day | 10-day | 15-day | 30-day |
|---|---|---|---|---|---|
| Company 1 | 1 | 4 | 9 | 11 | 22 |
| Company 2 | 1 | 4 | 8 | 12 | 26 |
| Company 3 | 2 | 8 | 13 | 17 | 37 |
Fourth line conveys that the traveler has to travel for 30 days.
Fifth line conveys on what days does he need to travel.
Note that:
- There is 10 days of consecutive travel from Day 1 to Day 10.
- There is 5 days of consecutive travel from Day 22 to Day 26.
- There is 15 days of consecutive travel from Day 33 to Day 47.
For first 10 days of consecutive travel, buying 5-day pass twice from company 1 or company 2 is actually cheaper than buying a 10-day pass from either of them. The minimum cost here will be 8 (4 * 2).
The cheapest cost for the next consecutive 5-day travel is 4. Hence by Day 26, fifteen travel days can be completed at a cost of 12 (8 + 4).
It is cheapest to buy 15-day pass from company 1 for consecutive travel from Day 33 to Day 47 at a cost of 11.
Hence the overall minimum travel cost is 23 (12 + 11). So the output is 23.
8) Cadets
Problem Description
In a military camp, temporary houses of all the cadets are placed on the north edge of a square field of Size ‘S’. All the cadets have an ID and their houses are allotted based on their IDs. So, the cadet with lowest ID will be allotted leftmost house and the cadet with highest ID will be allotted rightmost house.
They all are having a walk separately when there is an announcement that one of the cadets has tested positive for a deadly virus. They are asked to return to their houses immediately. While returning they are asked to first reach the column where their house is situated and then take a straight line to their house. The examples section provides a better understanding of this construct.
The movement of the cadets should happen according to the rules prescribed below.
- Cadets take steps in ascending order of their IDs one at a time. Every cadet has the same speed.
- While returning to his house, if the next block is not empty, the cadet will stop in his own block on his turn.
- In case two cadets are blocking each other’s path i.e. they are going in opposite direction, then the cadet with higher ID will move one row up (towards north if it is empty and there is no home) and allows the other cadet to move. The cadet with lower ID will then continue his journey.
- If a cadet stays in a block adjacent (up, down, left, and right blocks) to the infected cadet for more than ‘S’ seconds, then he will also get infected.
Your task is to calculate if and how many cadets get infected.
Constraints
3 <= Number of cadets <= 15
3 x 3 <= Size of the field (S) is minimum <= 15 x 15
Number of Cadets <= S (Size of the field)
1 <= ID of the Cadets <= 10000
No Cadet will be in any other Cadet's house and also cannot enter any other Cadet's house.Input
First line of the input will give the size of the square field
Second line of the input will give the cadet IDs and current position of all the cadets in the format
Second line of input comprises of pipe (|) separated string. Each such separated element is comprised of cadet ID and his current block position in the format.
Cadet ID : Current Block Position
First Cadet in the list is already infected.
Output
First line of output comprises of either an integer or a string.
• Print cadet ID of last cadet who entered his house, if all cadets are able to reach their houses. OR
• Print “Blocked” if two or more cadets are in deadlock and unable to move.
Second Line of output comprises of either an integer or a string.
• Print cadet ID of cadets who got infected in the order they appear in the input excluding the first cadet in the input who was the original carrier of the virus. OR
• Print “None” if there is no transmission to other cadets.
Explanation
Example 1
Input
3
10:6 |12:8 |14:4Output
Blocked
12 14Explanation
Size of the field is 3. Cadets 10, 12 and 14 are in blocks 6, 8 and 4 respectively.
Since the size of the field is 3 there are 9 blocks. The first row comprises of blocks 1, 2 and 3. Hence they are allocated to cadets 10, 12 and 14 respectively. Blocks 4 to 9 are available for travel.

Solution: The starting position of all the Cadets is shown in the first image. Next, Cadet 10 being the cadet with lowest ID, moves to position 5 at time t=1 (to reach the column of his house). Next, cadet 12 being the cadet with the second lowest ID, needs to move up but he is blocked by Cadet 10 at time t=2. Next, Cadet 14 needs to move right but he is blocked by cadet 10 at time t=3. He can move up but there is already a House (Denoted by H (cadet Number) example- H (10)).
It is now cadet 10’s turn to move again. However, since he is also blocked by cadet 14 at time t=4. So, all three Cadets are blocked.
Since all cadets are in close contact for 3 seconds or more all will get infected.
Example 2
Input
6
10:20|12:30|14:15|8:10|24:32|11:24Output
24
8Explanation
Size of the field is 6. Cadets 10, 12, 14, 8, 24 and 11 are in blocks 20, 30, 15, 10, 32 and 24 respectively.
Since the size of the field is 6 there are 36 blocks. The first row comprises of blocks 1 to 6. Hence, they are allocated to cadets 8, 10, 11, 12, 14 and 24 respectively. Blocks 7 to 36 are available for travel.
Solution: Starting position and next step taken by all the Cadets is shown in images. After that the positions, cadet ID – wise will be as following:
Initial Position-
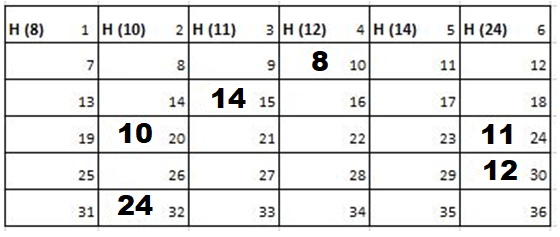
1st Iteration-
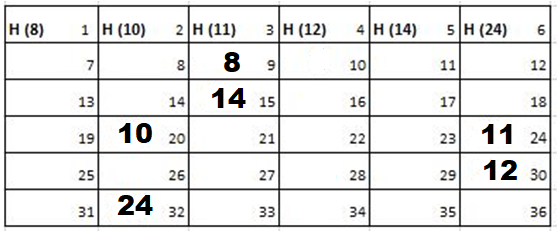
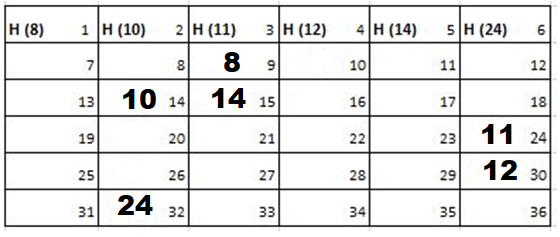
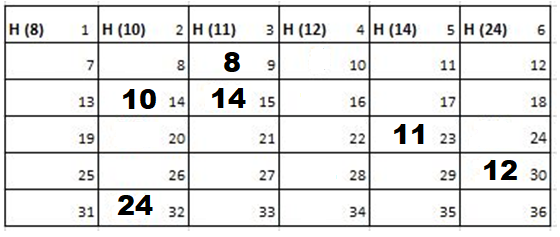
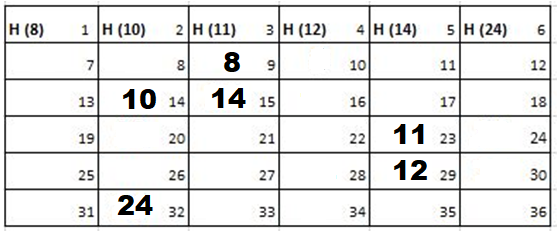
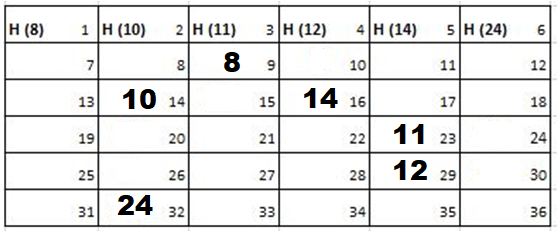
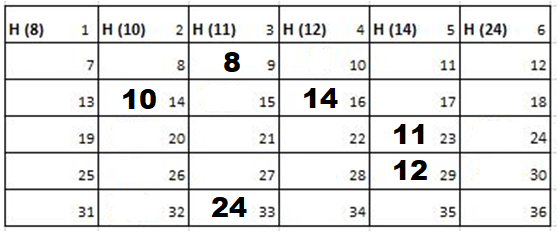
2nd Iteration-
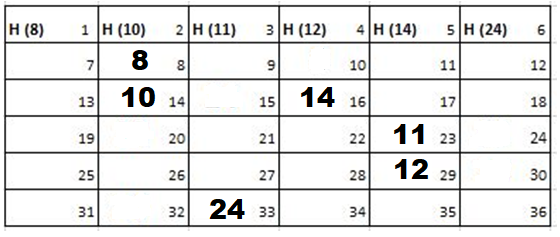
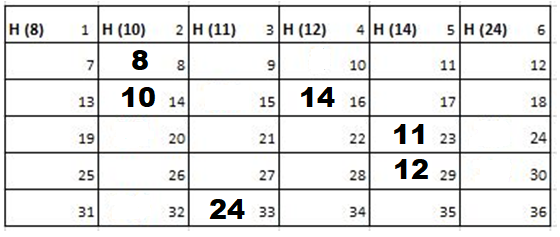
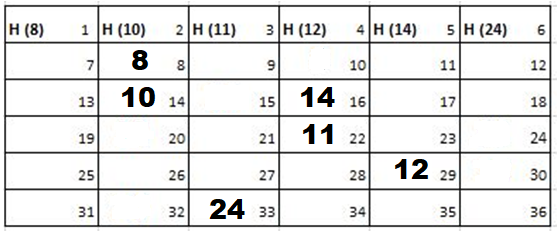
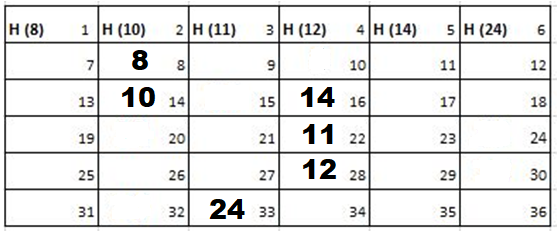
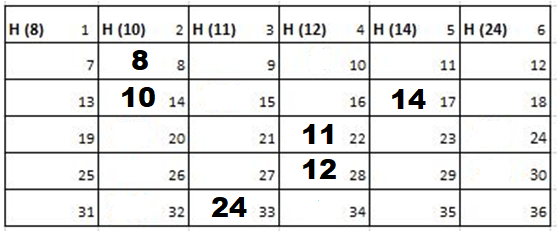
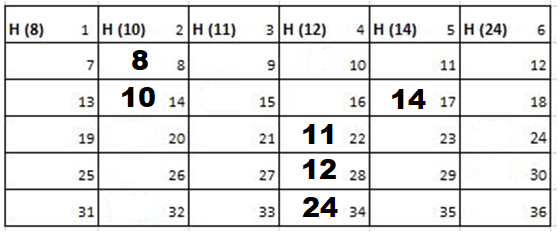
3rd Iteration-
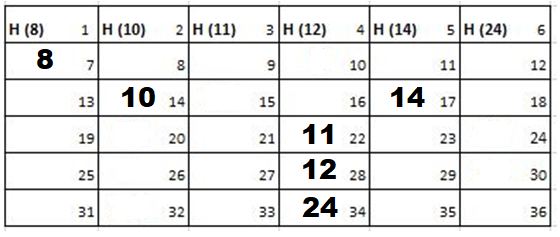
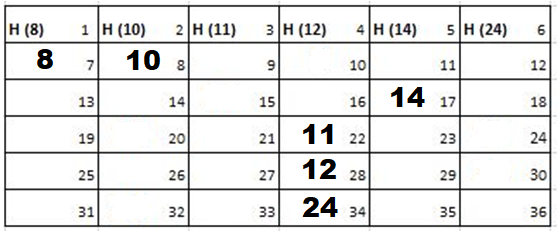
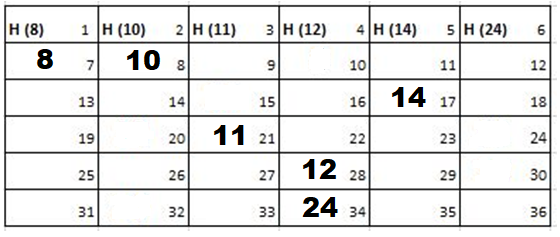
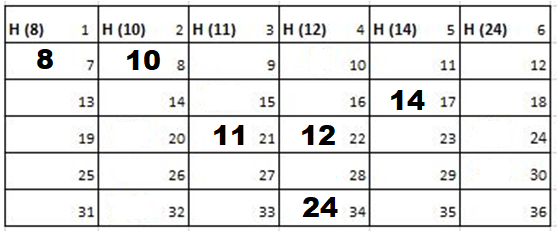
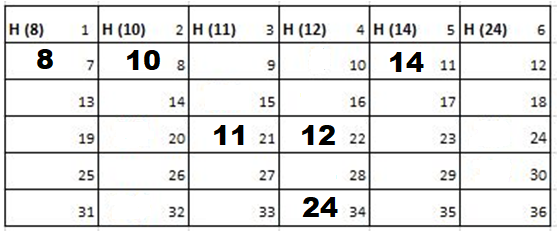
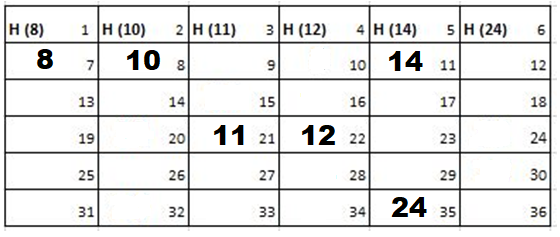
4th Iteration-
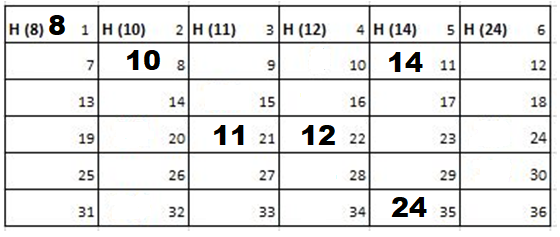
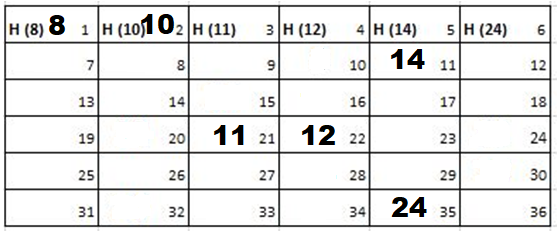
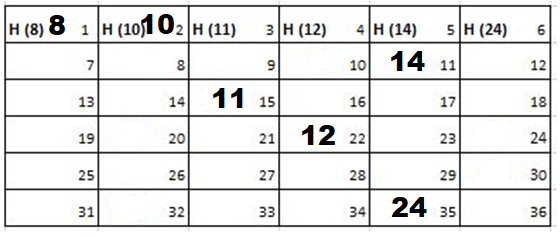
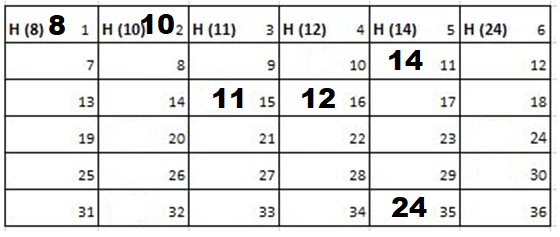
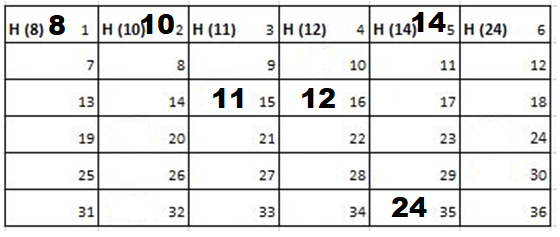
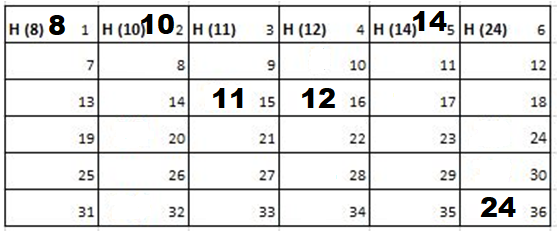
5th Iteration-
 .
.
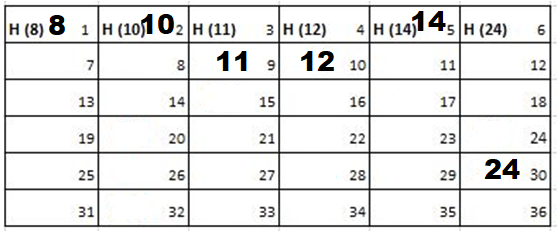
6th Iteration-
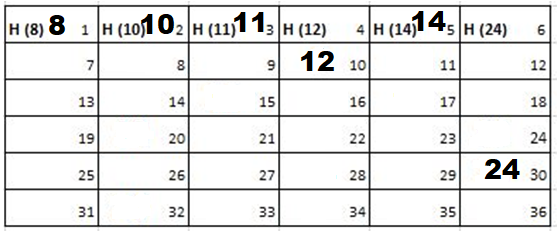
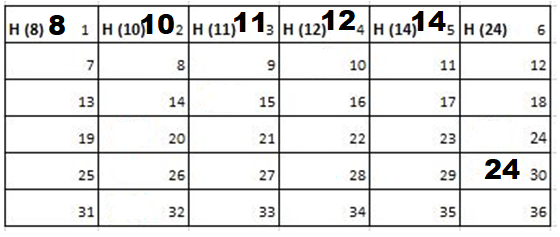
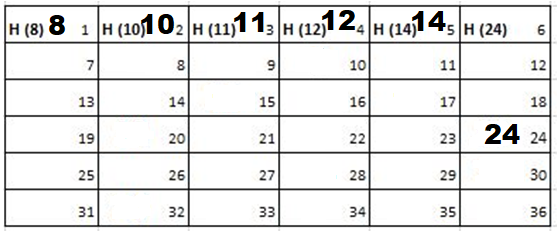
7th Iteration-
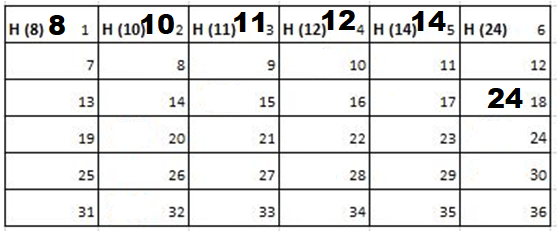
8th Iteration-
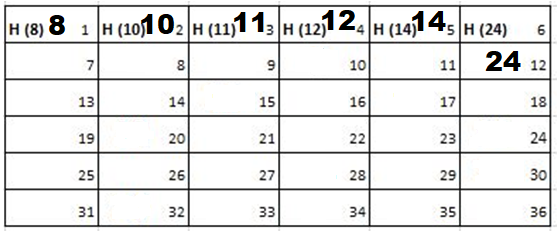
9th Iteration-
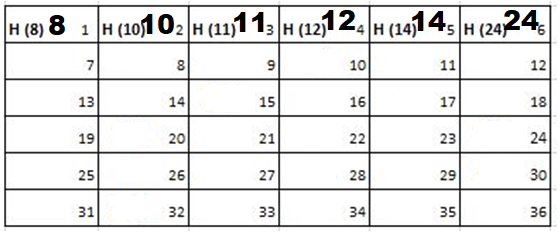
Output: First Line: 24 (ID of the Cadet who enters his house last)
Second Line: 8 (ID of the Cadets infected separated by space).
Since, cadet 8 is in contact with cadet 10 for more than 6 seconds i.e. from t=7 to t=18 so he got infected.
